 登录
登录


 2023.04.18
2023.04.18 6798
6798
4月13日,第六届云安全联盟大中华区大会(The 6th CSA GCR Congress)在上海成功举办!!
美国哥伦比亚大学常务副校长、美国艺术与科学院院士、IEEE & ACM Fellow 周以真 (Jeannette M. Wing) 通过视频连线,为与会者带来了关于可信AI的精彩演讲。她强调,AI系统在某些任务上已经取得了优异的表现,但也可能产生不公平和残酷的结果。为实现可信AI,我们需要从可信计算的基础上添加一系列属性,包括准确性、健壮性、公平性、问责制、透明度、可解释性和道德性。周以真校长提出了一种实现可信AI的方法,即将正式的数学社区、可信计算社区和人工智能社区结合在一起,采用验证和测试的常用方法来确保AI系统的正确性和满足特定属性。

以下为演讲内容
大家好,我是周以真,哥伦比亚大学负责研究的常务副校长兼计算机科学教授。今天,我想和大家谈谈我的新研究方向—可信AI。
对于某些任务,AI系统已经达到足够好的性能,可以部署在我们所在区域和家中。例如,物体识别有助于现代汽车检测车距。语音识别有助于个性化语音辅助对话,某些任务AI系统的表现甚至已经超越人类。Alphago 是第一个成为世界上最佳棋手的计算机程序。
AI的前景是巨大的,它们可以驾驶汽车,帮助医生更准确地诊断疾病,帮助法官做出更加一致的法庭判决,帮助雇主雇用更合适的求职者。
然而,我们知道AI系统可能是残酷和不公平的,如果我们在停车标志上涂鸦,AI系统将识别不出它是停车标志。如果在良性肿瘤的图片中加入噪声,系统将显示肿瘤是恶性的。美国法院使用的风险评估工具已显示出对黑人的偏见。企业招聘工具对女性存在偏见。
那么我们如何才能兑现AI能带来好处的承诺的同时,解决这些对人类和社会产生至关重要影响的场景?简而言之,我们如何才能实现可信AI?

我想谈谈可信计算中的可信AI。几十年来,计算机科学界在可信计算领域取得了一定进展,其中可信意味着一系列属性,包括可靠性,它做了正确的事吗?安全性,它无害吗? 防护性,面对攻击,它有多脆弱?隐私性,它是否保护了个人的身份和数据?可用性,当需要访问系统时,它是否可用?易用性,人类可以轻松地使用吗?计算就是硬件和软件的结合,当然还包括使用系统的人。

从可信计算到可信AI,我们正在不断提升。我们不仅需要可信计算的属性,同时还需要新的属性。我们期望这些计算系统具有准确性、稳健性、公平性、问责制、透明度、可解释性,甚至解决AI系统存在的道德问题。

所以我认为可信AI应该等于可信计算加上以下属性:准确性,与训练和测试的数据相比,AI系统在处理新的未知的数据方面表现如何?健壮性,输出结果对输入变化的敏感程度如何?公平性,结果是否公正?可问责性,谁或什么对结果负责?透明度,外部观察者是否清楚系统的结果是如何产生的?可解释性,系统的结果是否可以通过人类可以理解和/或对最终用户有意义的解释来证明是合理的,并且就道德问题而言,数据是否以道德的方式收集?结果将会以合乎道德的方式使用吗?
所以现在的问题是,我们如何才能实现可信AI?我想展示一种方法,当前正在采用的众多方法中的一种,就像验证和测试的常用方法。坦白说,我设定这个新的研究议题的最重要原因是将三个不同的社区聚集在一起,正式的数学社区、可信计算社区和人工智能社区。

所以从传统的应用形式看,我们有以下公式证明一个程序是正确的,或者表明系统满足一个特定的属性,这个公式有三个部分,M代表程序或协议,或者可以是一个循环分布式系统的数学模型。双转风格代表逻辑和嵌入该逻辑的工具,如模型检测器、定理证明器和可满足性模理论 (smt) 求解器。我们可以用它推理程序,P代表我们在传统形式验证中关心的透明度属性。我们试图证明一段代码的属性。我们使用布尔逻辑和离散逻辑。我们在这个领域取得了很大的进步,实际上已经将这些属性正式描述为安全属性和活跃属性。我们通常通过传统形式验证中的某种时序逻辑正式编写这些属性,有时会要求显式模型程序运行的系统环境,例如,e 可以是操作系统,也可以是特定网络物理系统的物理环境。

现在,我们想要验证的人工智能系统也正处于提升阶段。让我们重新解释一下 e, m 满足 p 的含义。这里的M可以是我们使用的机器学习的模型。但正如我们所知,这也只是一段代码,这让我觉得我们有希望将我们在正式方法中学到的一些技术应用到机器学习模型中。在这里,逻辑很可能在本质上是概率性的,因为 m 的概率性质以及信任规则的概率性质,如健壮性和公平性等属性。所以右边的 p 代表这个属性的透明性,与人工智能系统相关。正如我建议的那样,它很可能必须写出来,具有某种概率逻辑。那什么是最有趣和最重要的?思考如何使用形式逻辑验证人工智能系统是数据表征的显式,用于训练机器运行模型的数据,用于测试机器运行模型的数据,当然还有我们未知的数据,机器学习模型旨在用于实际部署。因此,人们可以将数据模型想象成类似于随机过程或数据分布的东西,例如,它生成需要验证 M 的输出的数据输入。
所以这个表达式就是我如何验证人工智能系统的可信属性。D,M 满足 p。我想在剩下的时间里很快地、更详细地解释这些元素。

请记住验证计算系统的传统方法在可信度方面的两个主要区别,分别是概率推理的需要,以及数据的作用。在本次演讲中,针对数据作用,我们只讨论两个关于未见数据的问题,以及我们要量化什么,因为这些是采用正式方法的社区以前不必解决的新问题。

那么为什么需要概率推理?首先,机器学习模型 M 在语义和结构上与典型的计算机程序不同,M 本质上是概率性的。在内部,模型本身对概率进行操作,并以指定的概率输出结果。在结构上,M 是机器生成的,不太可能是人类可读的,我们可以将其看作是另一种中间代码。这再次给了我希望,一些来自编程语言和形式化方法的技术可能会继续用于验证AI系统。P 可以在连续域上制定,而不仅仅是在离散域上,并且使用概率和统计中的表达式。深度神经网络的健壮性属性是连续变量的特征;公平属性的特征在于对真实损失函数的期望。差分隐私是根据相对于一个小的真实值的概率差异定义的。因此,可信ai的属性 p最好在这些连续域上制定。最后,我们用来验证满足 p 的逻辑可能是概率逻辑或混合逻辑。因此,我们需要适用于实数、非线性函数、概率分布、随机过程等的可扩展和/或新的验证技术。
现在,数据d的作用是什么?我喜欢区分可用数据,手头用于训练和测试的数据,以及未知的数据,即M 需要或预期在以前没有见过的情况下操作的数据。

因此,首先我们必须看看有关数据收集和分区的问题。我们如何将可用的给定数据集划分为训练集和测试集?在构建模型 M 时,我们可以针对所需属性 P 对这个分区做出什么保证?对于给定的属性P,多少数据足以构建模型M?添加更多的数据训练或测试 M 是否使其更健壮、更公平等。或者它对属性 P 没有影响。如果不具备所需的属性,那需要收集什么样的新数据?

如何标记未知的数据是一个很大的难题。我们如何标明数据或表征数据的属性?根据定义,它是未知的。那么我们怎么知道我们还没有看到?正如我之前提到的,我们可以通过它的参数将想法指定为随机过程或数据分布。我们可以使用概率编程语言,例如 stan,它用于指定统计模型。但是那些不适合常见统计模型(如正态分布或猜测分布)的大型现实世界数据集,或者具有数千个参数的大型数据集,更像是我们今天所看到的。我们收集大量数据并使用这些数据构建这些现代机器学习模型。还有一个关于标明未知的数据的问题,这打破了循环推理。为了标明未知的数据,我们需要做出某些假设并对未知数据运用这些假设,而这些假设与那些首先建立模型的假设不同。也就是说,我们如何才能相信 D 的规范?因此,为了打破这种循环推理,我们可能会采用几种方法。一个是统计工具的全部内容,我将在后面的胶片中具体介绍。另一个是从一个更小、足够简单的初始规范开始,可以通过手动检查。然后我们使用这个规范引导一个迭代的细化过程。这个过程很像正式方法中的反例引导抽象和细化。最后,未知数据的规范与训练和测试的数据规范有何关系?

尝试验证可信AI系统的第二个大的新问题是我们要量化什么?在传统的正式方法中,我们努力为所有 x.p(x) 证明这一点。 例如,对于一个特定变量的所有值,一些属性会得以实现。并且如果我们可以为相当多的变量的所有值证明它,那么对于实际使用的任何变量 P 肯定成立。但是对于AI系统,我们并不期望 M 对所有输入数据或所有数据集 D 都有效。

那我们可以量化什么?对于给定的 M,我们如何指定 P 应该具有的分布类别?它可能取决于属性。对于健壮性,在对抗性机器学习系统设置中,我们可能希望证明 M 对所有范数有界扰动 D 是健壮的。更有趣的是,我们可能希望证明 M 对于所有“语义”或“结构”的扰动是健壮的。例如,计算机视觉。在这里,我们知道给熊猫的图片添加一点噪音,在pandas可以看到、完整分类器,所以这个分类器对特定的扰动并不具备健壮性。
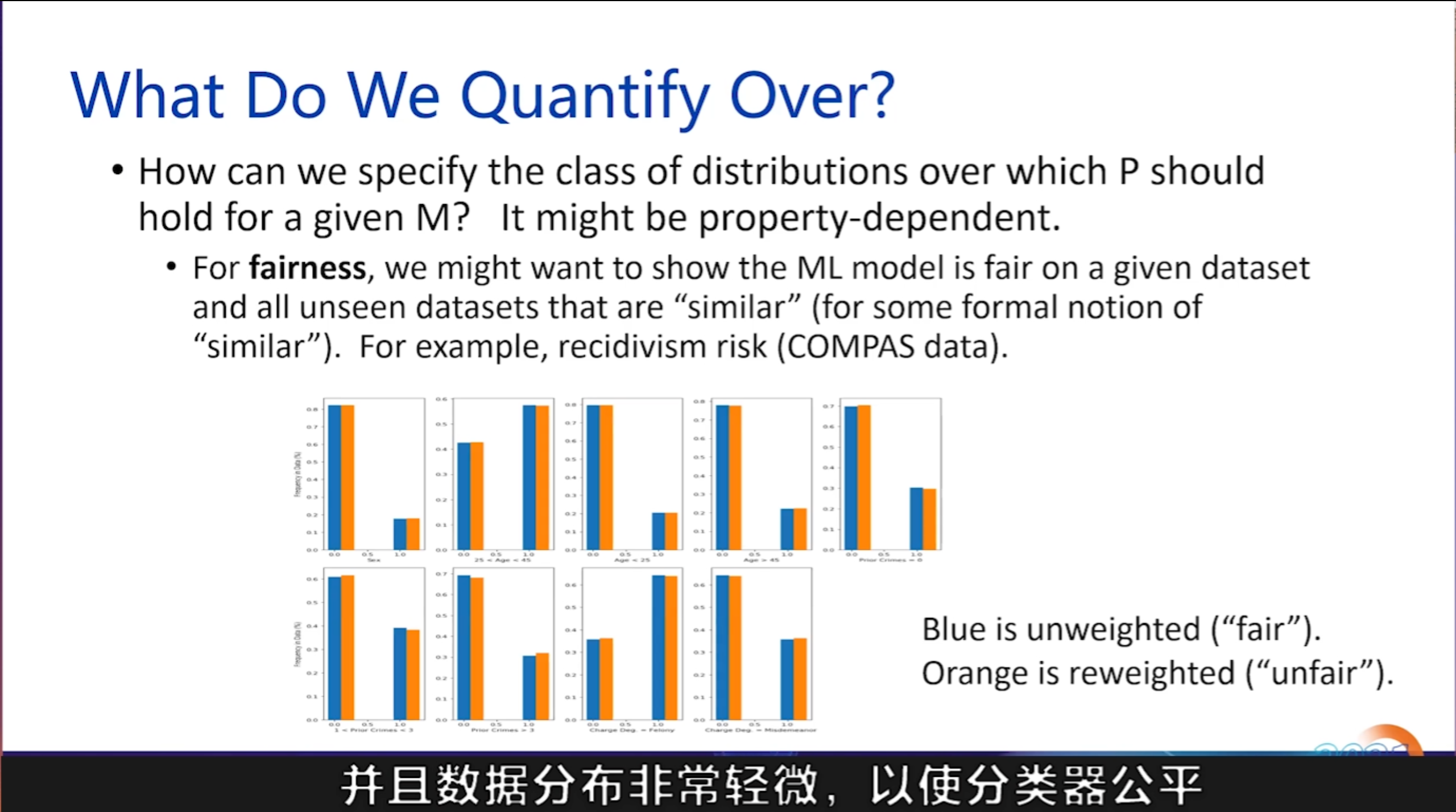
那对于像公平这样的不同属性应该怎么实现?为了公平起见,我们可能希望表明机器学习模型在给定数据集和所有未见过的数据集上是公平的,这些数据集对于某种正式的相似概念是相似的。例如,著名的 COMPAS 数据表明,对于累犯风险,该模型可能存在偏差。因此,在我与同事一起完成的去年在欧洲出版的一些工作中,我们展示了采用一个模型是多么容易,该模型在给定的数据分布上具有公平性,并且数据分布非常轻微,以使分类器公平。所以在这种情况下,这个公平模型不是很健壮,在我们发表的报纸上,我们展示了如何建立一个健壮的公平模型。
然后现在我们转向验证任务,一旦我们可以表征 m p 以确定,将存在很多问题,我们通常如何以自动化方式或半自动化方式验证?由于时间关系,我不打算详细讲解这些问题,但您可以在我去年 10 月发表的 CACM 文章中找到具体细节。

所以现在我想说正式方法有很多机会,而不仅仅是我提到的一种。我们可以查看任务并尝试使用任务帮助缩小研究空间。我们可以采取完全不同的方法,而不是在我们可以构建从一开始就具有可信属性的模型之后尝试验证。这是正确的构造方法。我们也想要组合。因此,如果您证明系统的一部分在某种程度上是可信的,对另一部分也是,您希望这两个部分的组合也是可信的。针对于特定的可信属性,这是一个非常大的挑战,对于传统的计算系统也是如此,以及众多传统的、可信的属性。继续回到我之前关于模型评估和模型检查的统计方法的评论,我们可以借用一些对我们有帮助的技术和统计数据,可通过敏感性分析、预测评分、预测检查、残差分析和模型批评表明初始模型是可信的。
到这里,我今天的分享就要告一段落了,最后想再次强调我的研究内容,可信AI能通过包含4部分的表达式得以实现,谢谢大家。

手机:19925407556
邮箱:info@c-csa.cn
 雷池WAF
雷池WAF 安恒信息
安恒信息