 登录
登录
 2025.04.09
2025.04.09 11798
11798
随着AI技术在各行业的快速渗透,其带来的风险也日益凸显——从数据偏见、隐私泄露到模型滥用和伦理争议。云安全联盟(CSA)大中华区发布的《AI模型风险管理框架》为组织提供了一套系统化方法论,通过模型卡片、数据手册、风险卡片和场景规划四大工具,构建覆盖AI全生命周期的风险管理体系。

《AI模型风险管理框架》(以下简称《框架》)探讨了模型风险管理及其在负责任的AI开发中的重要性,深入分析了有效模型风险管理框架的四大支柱及其如何协同合作,从而形成一个全面的模型风险管理方法。
《框架》面向开发和部署机器学习模型且对AI风险有共同兴趣的广泛读者群体,包括AI模型开发与实施的从业者(机器学习工程师和数据科学家、AI开发人员和项目经理)、AI治理与监管的利益相关者(风险管理专业人士、合规官员和审计员、业务领导者和高管、沟通与公共关系专业人士)。
一、AI模型风险:从“黑箱”到透明治理
《框架》开篇即指出:“模型风险源于模型本身的固有限制”,这一论断揭示了AI风险管理的本质挑战。报告系统性地将模型风险归纳为五大来源,为不同行业的风险管理提供了清晰的问题框架:
1. 数据质量陷阱:训练数据的不准确、不完整或片面性,如金融风控模型使用非代表性数据导致风险评估失真。
2. 架构设计缺陷:模型选择不当或算法缺陷,如用线性模型预测非线性市场波动。
3. 顶尖模型固有风险:包括生成式AI的幻觉、有害内容生成等系统性风险。
4. 实施操作风险:从编码错误到提示注入等新型攻击面。
5. 环境演化风险:经济周期、政策变化等外部因素导致的模型失效。
传统“事后补救”模式已无法应对AI的复杂性。《框架》强调,风险管理需贯穿开发、部署、监控、迭代全流程,其核心目标是:
1. 透明化:打破“黑箱”,让利益相关者理解模型逻辑与局限;
2. 可控化:通过结构化工具预判风险并制定缓解策略;
3. 合规化:满足欧盟《AI法案》、NIST AI RMF等全球监管要求。
二、四大支柱解析:从理论到落地的关键工具
CSA AI模型风险管理框架通过整合四个核心组件来构建:
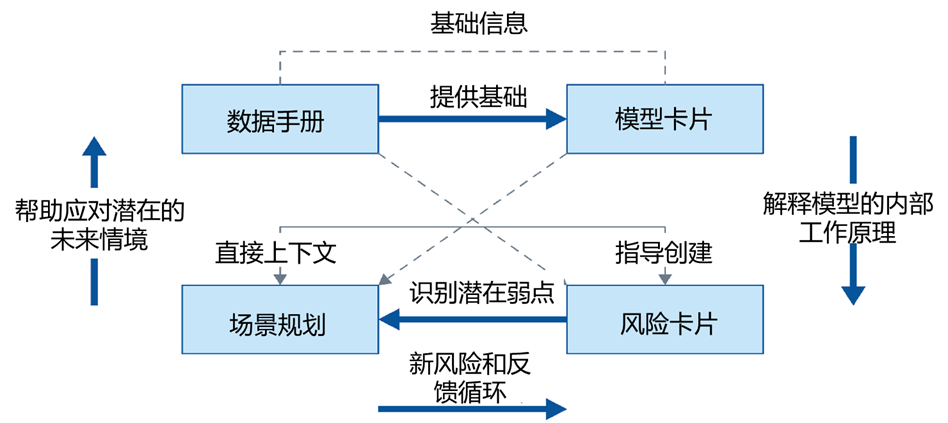
CSA AI模型风险管理框架
1. 模型卡片(Model Cards):理解模型
为机器学习模型提供清晰简洁的窗口,它详述了模型的目标、训练数据、能力、对抗性AI防御、限制和性能,增强透明度并促进知情使用。模型卡片是模型的标准化文档,回答以下关键问题:
· 用途与边界:模型设计目标是什么?哪些场景不适用?
· 数据溯源:训练数据来源、规模及潜在偏见;
· 性能指标:准确率、公平性(如不同性别/种族的F1分数差异);
· 对抗性防御:是否通过对抗测试?抵抗提示注入的能力如何?
2. 数据手册(Data Sheets):检查训练数据
详尽描述用于训练机器学习模型的数据集。记录创建过程、组成部分(数据类型和格式),预期用途、潜在偏见、限制以及与此相关的伦理考量。数据手册聚焦训练数据的“质量基因”,包括:
· 数据构成:类型、分布、标注方法;
· 伦理审查:是否包含敏感信息?获取是否合规?
· 预处理步骤:如何清洗噪声数据?如何处理缺失值?
3. 风险卡片(Risk Cards):识别潜在问题
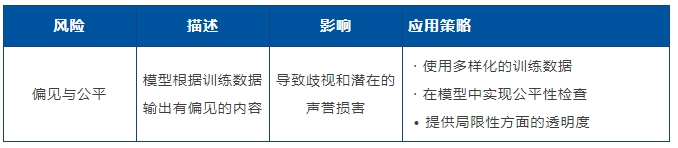
总结人工智能模型所涉及的关键风险。它系统地识别、分类并分析可能出现的问题,在开发或部署过程中重点关注已观察到的风险,并解释当前和计划中的补救措施,概述预期用户行为以确保负责任地使用该模型。风险卡片以结构化表格系统化梳理风险,例如:
4. 场景规划(Scenario Planning): “假设”方法
探索一个模型可能被滥用或出现故障时所处环境下产生假设状况, 帮助识别未预见到的风险并制定缓解策略。通过“假设分析”模拟极端情况,例如:
· 积极情景(例如,提高生产力、改善教育);
· 消极情景(例如,语言武器化、信息操纵);
场景规划关键步骤:组建跨职能团队(技术、法务、伦理专家)→ 基于业务影响定义风险优先级→ 制定应急计划(技术控制、流程保障)。
三、框架价值:从风险防御到业务赋能
《框架》通过四大支柱(模型卡片、数据手册、风险卡片、场景规划)构建的全面风险管理体系,为组织提供了多维度的价值实现路径。基于报告原文中明确的九大优势,我们将其归纳为三大核心价值维度:
1. 透明化治理:构建可信AI的基石
· 模型卡片提供模型目标、训练数据、性能指标的完整视图,使开发者和用户都能理解模型的能力边界。例如,某医疗AI公司通过公开模型卡片中"不适用于儿科诊断"的明确标注,显著降低了临床误用风险。
· 数据手册详细记录数据来源、预处理方法和潜在偏差,为数据质量提供可审计的证明。例如,金融领域应用显示,完整的数据溯源文档可使模型合规审查效率提升40%。
· 风险卡片系统化披露已知风险及缓解措施,如内容审核AI标注"对方言识别准确率不足85%",促使企业配置人工复核流程。
2. 主动化风控:从应急响应到预防性管理
· 场景规划通过模拟极端情况(如经济危机下的信贷模型失效)提前制定应急预案,如某银行借此将风险事件响应时间从72小时缩短至4小时。
· 持续监控机制追踪模型漂移指标(如F1值波动、数据分布偏移),制造业企业通过设置自动化警报,将预测性维护模型的误报率降低58%。· 风险分级管控基于风险卡片中的严重性/可能性评估,某电商平台将80%资源集中于解决"价格歧视"等高影响风险,合规成本降低35%。
3. 价值化输出:风险管理即竞争优势
· 信任资产化:社交平台将模型透明度文档作为付费API服务的差异化卖点,企业客户续约率提升27%。
· 合规前置化:数据手册中的隐私保护措施直接映射GDPR要求,使某跨国企业节省年度审计费用超200万美元。
· 决策智能化:风险卡片与业务KPI联动,物流公司通过"天气影响预测偏差"风险优化路线算法,年度运输成本下降15%。
四、实施路径:三大关键行动建议
1. 高层驱动与文化植入
· 董事会需将AI风险管理纳入战略议程,设立跨部门AI治理委员会;
· 通过培训将“负责任AI”理念融入开发、产品、运营团队日常。推荐通过CSA大中华区推出的人工智能安全认证专家课程(CAISP),系统化地提升团队在AI安全领域的专业能力,确保AI项目的负责任开发和运营。
2. 小步快跑,从试点到推广
· 优先在高风险场景(如信贷审批、医疗诊断)试点四大工具;
· 利用自动化工具(如MLOps平台)降低文档维护成本。
3. 持续监控与迭代
· 建立模型性能“健康指标”(如数据漂移警报、公平性阈值);
· 每季度更新风险卡片,适配新型威胁(如AI生成的深度伪造攻击)。
五、AI 模型风险管理在行动:社交媒体内容审核实战案例
《框架》用一个实际例子展示了AI模型风险管理的真正价值——它将抽象概念转化为确保模型负责任和安全部署的具体步骤的能力。下面的图表描述了场景规划的整体流程。

使用模型卡片、风险卡片和数据手册进行场景规划
1. 社交媒体内容审核的大型语言模型
这个案例研究探讨了使用大型语言模型(LLM)进行社交媒体内容审核的潜在风险和机会,并利用模型卡片、风险卡片和数据手册进行场景规划。
注意:这里展示的模型卡片、数据手册和风险卡片是为了说明目的而进行的简洁总结。在实际应用中,这些文档会更加全面,包含详细的信息。
2. 模型卡
模型名称:社交达人- 内容审核大型语言模型
日期:此文档中的信息截至2024年4月1日是最新的,除非下面另有说明。
模型目的:“社交达人”旨在分析社交媒体内容并识别可能违反平台政策的行为,包括仇恨言论、虚假信息和骚扰。它通过标记需要审核的内容来协助人类审核员。
模型输入:“社交达人”接收来自社交媒体帖子、评论和消息的文本数据。
模型输出:预训练的大型语言模型为每条内容分配一个风险评分,表明其违反平台政策的可能性。
模型训练数据:“社交达人”在大量标记过的社交媒体内容数据集上进行训练,包括违反政策的示例和可接受的内容。这些数据不断更新,以反映不断演变的语言模式和文化细微差别。
性能指标:“社交达人”的性能通过准确性(正确识别违规行为)、精确度(避免误报)和召回率(捕获大多数违规行为)等指标进行评估。
3. 数据手册
数据手册提供了对训练模型所用数据集的透明视角。它们揭示了数据的来源、特征和规模,使人能够理解塑造“社交达人”响应的基础。
数据手册1:社交媒体政策指南
日期:此文档中的信息截至2024年4月1日是最新的,除非下面另有说明。
描述:这份数据手册概述了特定社交媒体平台的社区指南和内容审核政策,LLM 被训练用来识别违反这些政策的行为。
用例:使LLM能够识别并标记违反平台规则的内容,促进安全和包容的在线环境。
来源:来自主要社交媒体平台的公开可用的社区指南和内容审核政策。
特征:概述禁止内容类别(例如,仇恨言论、欺凌、骚扰)的结构化数据,以及具体示例和定义。数据规模取决于平台,通常从数万字到数十万字不等。
4. 风险卡
根据“社交达人”模型卡片和概述其训练数据的数据手册,已经开发了一套风险卡片,以主动识别潜在问题。这些风险卡片深入探讨了“社交达人”的输出可能被误解或滥用的场景。
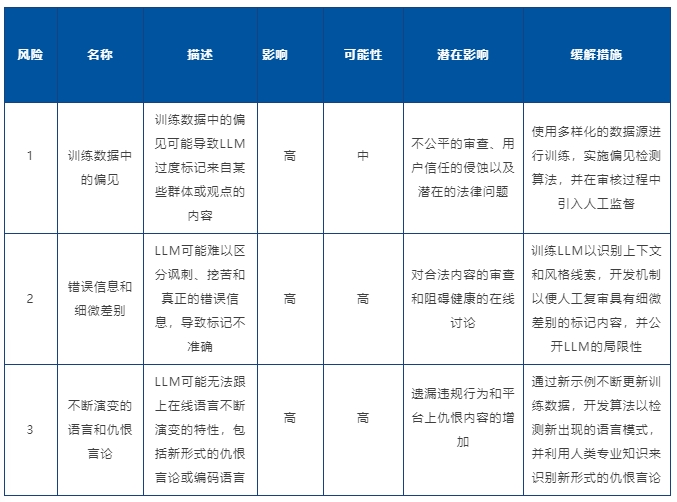
5. 场景规划
设想“社交达人”在现实世界情境中的互动。这一部分探索了一些场景,以观察模型可能的反应。
场景1:有效审核(广泛采用 + 降低风险)
描述:“社交达人”有效地协助人类审核员识别和移除有害内容,从而营造一个更安全、更具包容性的在线环境。实施的保障措施最小化了偏见,并确保了LLM的负责任使用。
好处:提高内容审核效率,减少用户接触有害内容的机会,以及更积极地在线体验。
挑战:不断适应LLM以应对不断演变的语言模式和在线趋势。确保能够获取足够的高质量训练数据,以保持模型的有效性。
总结:“社交达人”,作为一个大型语言模型(LLM),可以协助人类审核员进行内容审核。然而,训练数据中存在偏见的风险,可能导致不公平的内容标记。为了减轻这一风险,将使用多样化的数据源和偏见检测算法来训练LLM。此外,将在审核过程中保持人工监督。虽然"社交达人"有潜力提高在线安全,但解决偏见并确保负责任地使用对于其成功至关重要。
6. 总结
“社交达人”在内容审核方面虽然有价值,但面临放大偏见的风险。有限的人工监督可能导致训练数据中的偏见未被检查,从而导致对某些群体的不公平内容标记。需要对训练数据进行彻底的偏见审查,透明公开LLM的局限性,并对所有标记内容进行强制性人工复审,以解决这一问题。
六、未来展望:AI风险管理的下一站
随着生成式AI爆发,《框架》预见以下趋势:
· 监管协同:NIST AI RMF与ISO 42001等标准将进一步融合;
· 技术赋能:可解释AI(XAI)、联邦学习等技术将增强风险可视性;
· 全球化挑战:跨境数据流动与地缘政治对AI治理的影响需纳入场景规划。
AI的风险与价值如同一枚硬币的两面。《框架》提供的不仅是工具,更是一种“预防优于补救”的战略思维。唯有将风险管理融合到AI生命周期,才能真正实现“可信AI”的承诺。
《AI模型风险管理框架》为组织提供了实施AI风险管理的指导,但在实际操作中,组织可能需要更深入的理解。CSA大中华区发布的CAISP认证培训项目正好填补了这一空白。该培训项目不仅涵盖了《框架》的核心内容,还通过跨学科和实践导向的教学方法,加强了学员在AI安全方面的专业知识。通过CAISP认证,学员能够更有效地将理论知识应用于实际工作中,推动AI安全实践的进步。
AI安全能力提升

CSA大中华区推出的人工智能安全认证专家(CAISP)认证培训课程旨在为从事AI(含AI安全)的研究、管理、运营、开发以及网络安全等从业人员提供一套全面覆盖AI安全领域、跨领域综合能力培养、实践导向与案例分析、结合全球视野与法规治理的AI安全课程。
课程专注于理解人工智能安全的治理与管理环境,学习AI安全的术语与安全目标,针对于算法、模型以及数据安全和隐私进行学习,全面提升对AI安全风险的识别、评估与测评等实战化能力;课程还涵盖了AI安全国内外的法律法规框架,并通过实际案例,探讨如何在组织中实施AI安全;此外,学员还将具体学习如何应对AI安全的风险与挑战,包括应对数据投毒、对抗性攻击和供应链威胁等多种安全挑战。
致谢
《AI模型风险管理框架》由CSA云安全联盟编写,并由CSA大中华区AI安全工作组完成翻译并审校。
翻译组成员:
郭建领 卞超轶 黄鹏华 王绪国 卜宋博 张 淼 潘季明 张 亮
审校组成员:
高健凯 卜宋博
(以上排名不分先后)

手机:19925407556
邮箱:info@c-csa.cn
 雷池WAF
雷池WAF 安恒信息
安恒信息